
Kaggle Digit Recognizer series
Sample data from the Machine Learning class is arranged as one sample per row with data values ranging from just a bit below 0 to a little above 1. Each digit image is a flattened 20×20 grey scale pixel array. The Kaggle data is arranged similarly but values range from 0 to 255. Kaggle digits are flattened 28×28 pixel arrays. The difference in value ranges should not be a problem for the exisiting code. The neural network input layer for Kaggle data will have 784 units vs the 400 used for the ML class data.
So the only code modification at this point is changing:
input_layer_size = 400; % 20x20 Input Images of Digits
hidden_layer_size = 25; % 25 hidden units
num_labels = 10; % 10 labels, from 1 to 10to this:
input_layer_size = 784; % 28x28 Input Images of Digits
hidden_layer_size = 25; % 25 hidden units
num_labels = 10; % 10 labels, from 1 to 10So we should be ready to go! The first thing we see running the top level Octave code is an image of a random selection of input samples.

What? This can’t be right! Well it doesn’t really matter to the performance of classifying digit samples. But it is rather awkward to turn your head 90 degrees and look in a mirror at the computer display so lets fix this. The problem is caused by a difference of opinion on up/down/left/right for the two data sources. To fix this the displayData() function needs a change where the display_array is being accumulated. Change this:
reshape(X(curr_ex, :), example_height, example_width) / max_val;to this:
reshape(X(curr_ex, :), example_height, example_width)' / max_val;That’s it. Just transpose the result of reshape. A single character change.
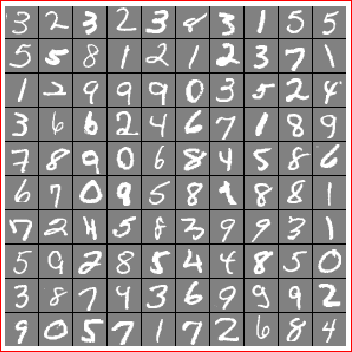
Much better.
