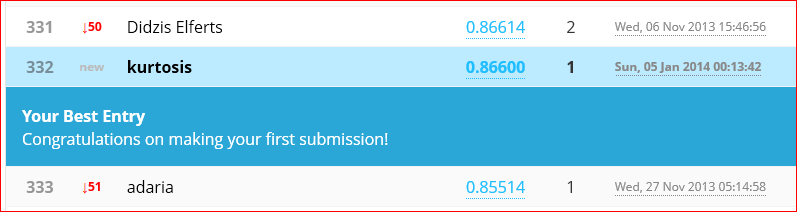
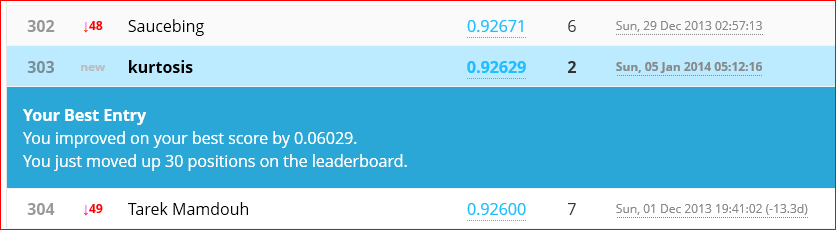
Wow! Andrew Ng’s Machine Learning Class via Coursera was amazing. What next? For more Andrew it looks like the iTunes store has two different versions of a 2008 on campus course. Access these via iTunesU > Universities & Colleges > Stanford > Engineering. Both seem to have the same 20 lecture videos.
This one  looks like a newer reorganization of the material with topic titles interspersed among the videos. Where those topics lead is a mystery, they do not appear active on Win iTunes but might go somewhere on Apple hardware.
looks like a newer reorganization of the material with topic titles interspersed among the videos. Where those topics lead is a mystery, they do not appear active on Win iTunes but might go somewhere on Apple hardware.
update: There is a much better organized version of this material at the stanford engineering everywhere site. Don’t bother with the iTunes version. This one has links to a syllabus, lecture videos and pdf’s, problem assignments and solutions, and other reference material.
Also online there is tutorial material on Unsupervised Feature Learning and Deep Learning which lists Andrew as the first contributor.
Lots of references from the Coursera Machine Learning wiki page ML:Useful Resources need to be explored too. You might need to be signed in on Coursera to access this page.
And finally there are two courses of interest on the Stanford Open Classroom site. Both Machine Learning and Unsupervised Feature Learning and Deep Learning have some interesting bits but neither seems to be complete. Works in progress? Or early MOOC efforts that won’t ever be finished?